HTTP Requests
Requests¶
When building or interacting with web APIs (Application Programming Interfaces), it's essential to understand how communication between clients (like your browser or an application) and servers occurs. HTTP (Hypertext Transfer Protocol) is the foundation of this communication. HTTP methods (or verbs) are a key part of how clients request actions from the server and how the server responds.
In this article, we'll cover the most common HTTP methods, their purposes, and how they form the basis for interacting with APIs.
HTTP Protocol¶
HTTP is a protocol that defines how messages are formatted and transmitted between a client (such as a web browser) and a server. It also determines how servers respond to various requests.
sequenceDiagram
participant Client
participant Server
Client->>Server: HTTP Request (e.g., GET, POST)
Server-->>Client: HTTP Response (e.g., Data, Status Code)When you interact with an API, you use HTTP to make requests. Each request is an action you want the server to perform. The server then sends the response back, usually in the form of data, a status code, and/or a message.
HTTP Methods¶
An HTTP method is a way for a client (such as a web browser) to communicate with a server by specifying the desired action on a resource. HTTP methods are part of the HTTP protocol, which governs how data is transferred over the web.
Safe Methods¶
A method is considered safe if it does not modify any resources on the server. It should only retrieve or provide information without making changes to the server's data or state. Even though the server might perform internal operations (such as logging), the state of the resources remains unaffected.
GET, HEAD, and OPTIONS are safe.
Idempotent Methods¶
A method is idempotent if making multiple identical requests has the same effect as making a single request. In other words, whether you call the method once or multiple times, the result will be the same, without causing additional side effects from repeated requests. **If method is idempotent, this is safe*
GET, PUT, DELETE, HEAD, OPTIONS, and PATCH are idempotent.
Methods¶
There are several HTTP methods, each with a specific role. Let’s explore the most commonly used ones:
1. GET¶
- Purpose: Retrieve data from a server.
- Use Case: When you want to fetch information without modifying anything.
- Example:
- Retrieving a list of products from an online store.
- Accessing a user’s profile information.
GET /users/123 HTTP/1.1
In this example, the client is requesting information about a user with ID 123.
How it works
When you send a GET request, you're asking the server to send back the requested resource.
It’s a read-only operation, meaning it doesn’t change any server data.
2. POST¶
- Purpose: Send data to the server to create a new resource.
- Use Case: When you’re submitting form data, creating a new user account, or adding an item to a database.
- Example:
- Posting a new blog article.
- Submitting a registration form to create a new user.
POST /users HTTP/1.1
Content-Type: application/json
{
"name": "John Doe",
"email": "[email protected]"
}
In this example, the client is sending a new user’s data to the server, and the server will create that user in its database.
How it works
The client sends data to the server, typically in the body of the request. The server processes this data and creates a new resource based on it.
3. PUT¶
- Purpose: Update an existing resource on the server.
- Use Case: When you need to update data, like modifying a user's profile or changing the details of an existing item.
- Example:
- Updating a product’s price.
- Changing user account information.
PUT /users/123 HTTP/1.1
Content-Type: application/json
{
"name": "John Smith",
"email": "[email protected]"
}
Here, the client is updating the details of the user with ID 123.
How it works
This method usually replaces the entire resource with the new data you send.
4. PATCH¶
- Purpose: Partially update an existing resource on the server.
- Use Case: When you need to update only specific fields of a resource, like changing just the email address of a user.
- Example:
- Changing the stock quantity of an item in a store.
- Updating a single field of a user's profile without sending all the data.
PATCH /users/123 HTTP/1.1
Content-Type: application/json
{
"email": "[email protected]"
}
In this example, only the email field of the user with ID 123 is updated.
How it works
Unlike PUT, PATCH only updates the specific fields provided in the request body.
5. DELETE¶
- Purpose: Delete a resource from the server.
- Use Case: When you need to remove data, such as deleting a user account or removing a post.
- Example:
- Deleting a product from an online store.
- Removing a user’s account from the system.
DELETE /users/123 HTTP/1.1
How it works
The server deletes the specified resource, and after the operation, the resource is no longer available.
6. HEAD¶
- Purpose: Retrieve metadata about a resource without the actual resource data.
- Use Case: When you want to check if a resource exists or gather information like the size or modification date without downloading the entire resource.
- Example:
- Checking if a file is available on a server before downloading it.
- Verifying if a webpage is accessible without loading the content.
HEAD /users/123 HTTP/1.1
In this example, the client is requesting metadata (like content type or last modified date) about the user with ID
123, but without fetching the user's full data.
How it works
A HEAD request is similar to GET, but it only retrieves the headers, not the body of the response.
7. OPTIONS¶
- Purpose: Retrieve information about the communication options available for a specific resource or the server as a whole.
- Use Case: When you need to know which HTTP methods (GET, POST, PUT, etc.) are supported by the server or resource.
- Example:
- Checking which methods are allowed for a particular endpoint.
- Discovering available server capabilities before making further requests.
OPTIONS /users HTTP/1.1
In this example, the client is asking the server which HTTP methods (e.g., GET, POST, PUT) are available for the
/users resource.
How it works
The client sends an OPTIONS request to a server, and the server responds with the allowed methods or other relevant communication options.
Endpoints¶
The route in a URL refers to the specific part that comes after the domain name and defines the path to a particular resource or page on the server. In this structure:
https://example.com/products/electronics
https://example.comis the domain name./products/electronicsis the route.
The route typically includes the path and any parameters or queries that specify what the user is requesting, like
/docs, /about, /contact, etc. It's used by the server or client-side router to determine which content to display.
An API endpoint is a specific path where the client can send requests. The endpoint typically includes a route (or URL) and is associated with an HTTP method.
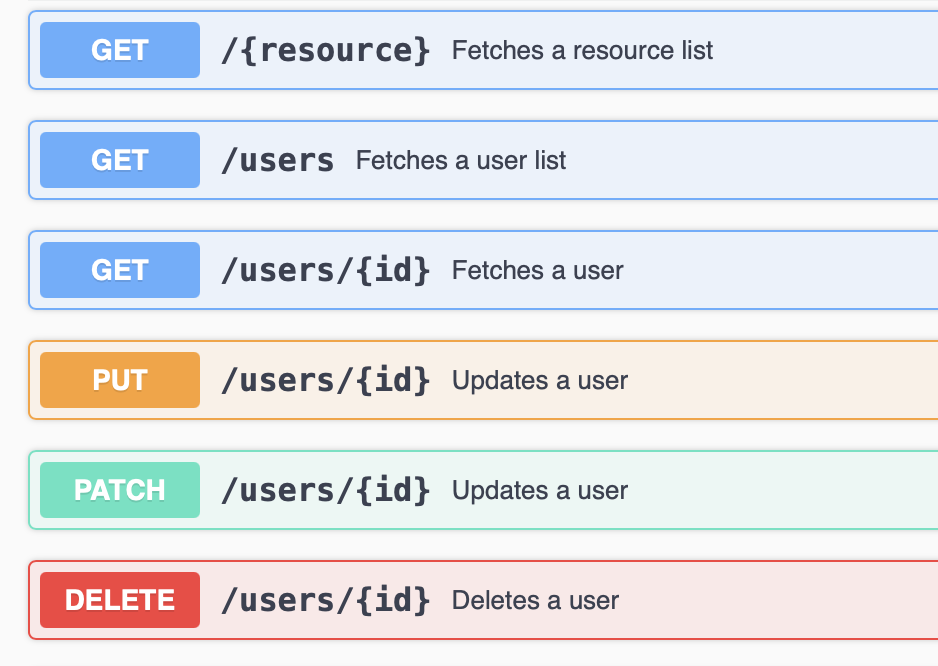
Route /users could be an endpoint for a user-related API.
A route can often include parameters to identify specific resources, like /users/123 where 123 is the user’s ID.
When interacting with an API, you’ll combine a method with an endpoint to perform an action.
- GET
/users– Retrieve a list of users. - GET
/users/123– Retrieve information about the user with ID123. - POST
/users– Create a new user. - DELETE
/users/123– Delete the user with ID123.
Info
HEAD and OPTIONS methods are not explicitly declared in API specification. You can use HEAD, when interacting with any GET endpoint and OPTIONS, when interacting with any other endpoints.
Response¶
An HTTP response is a message sent by a server to a client in response to an HTTP request. It contains status information about the request and the requested content, if applicable. The response is composed of several key components:
-
Status Line: This line includes the HTTP version, a status code, and a reason phrase. The status code indicates `the outcome of the request, while the reason phrase provides a textual description.
HTTP/1.1 200 OK -
Headers: HTTP headers provide additional context and metadata about the response. Headers can include information about the content type, content length, caching policies, server information, and more.
Content-Type: application/json Content-Length: 1234 -
Body: The body of the response contains the actual content returned by the server. Depending on the request and the endpoint, this content can be in various formats, such as HTML, JSON, XML, or plain text.
{ "id": 123, "name": "John Doe", "email": "[email protected]" }
The structure of an HTTP response looks like this:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1234
{
"id": 123,
"name": "John Doe",
"email": "[email protected]"
}
Status Codes¶
HTTP status codes are standardized codes returned by the server in response to an HTTP request. They provide information about the status of the request, and they are grouped into five categories, each representing a different type of response.
1. 1xx Informational¶
These codes indicate that the request has been received and is still being processed. They are primarily used for communication between the client and server during the request lifecycle.
- 100 Continue: The server has received the initial part of the request and the client should continue with the
rest of the request. This status is often sent in response to a
POSTorPUTrequest where the client must send a large amount of data. - 101 Switching Protocols: The server is switching protocols as requested by the client. This is commonly used when a client requests to switch from HTTP to a different protocol, such as WebSocket.
2. 2xx Success¶
These codes indicate that the request was successful and the server has fulfilled the request.
- 200 OK: The request was successful, and the server returned the requested data.
- 201 Created: The request was successful, and a new resource was created (often seen in POST requests).
- 204 No Content: The request was successful, but there is no content to return (common for DELETE requests).
3. 3xx Redirection¶
These codes indicate that further action is needed to complete the request.
- 301 Moved Permanently: The requested resource has been moved to a new URL permanently.
- 302 Found: The requested resource resides temporarily at a different URL.
- 304 Not Modified: The resource has not changed since the last request, allowing the client to use a cached version.
4. 4xx Client Error¶
These codes indicate that there was an error with the client's request.
- 400 Bad Request: The server could not understand the request due to invalid syntax.
- 401 Unauthorized: Authentication is required, and the client has not provided valid credentials.
- 403 Forbidden: The server understood the request, but refuses to authorize it.
- 404 Not Found: The server cannot find the requested resource.
5. 5xx Server Error¶
These codes indicate that the server failed to fulfill a valid request.
- 500 Internal Server Error: The server encountered an unexpected condition that prevented it from fulfilling the request.
- 502 Bad Gateway: The server received an invalid response from an upstream server while trying to fulfill the request.
- 503 Service Unavailable: The server is currently unable to handle the request due to temporary overload or maintenance.
Media Types (MIME Types)¶
Media types, also known as MIME types (Multipurpose Internet Mail Extensions), are a standard way of indicating the nature and format of a file or data being transmitted over the Internet. They help clients and servers understand how to process and display the content being sent or received.
A MIME type consists of two parts: a type and a subtype, separated by a slash (/):
- Type: The general category of the data, such as
text,image,audio,video, orapplication. - Subtype: A specific format of the type.
Common Media Types¶
Here are some common MIME types you might encounter:
- text/html: HTML documents.
- text/plain: Plain text files.
- application/json: JSON data.
- application/xml: XML data.
- image/jpeg: JPEG images.
- image/png: PNG images.
- application/x-www-form-urlencoded and multipart/form-data: Form data.
- application/octet-stream: Binary data (used for files that do not fit into other categories).
Form Data¶
Form data is a media type used when submitting data from an HTML form to a server. It typically uses the
application/x-www-form-urlencoded or multipart/form-data MIME types.
-
application/x-www-form-urlencoded: This is the default encoding for HTML forms. In this format, the form data is encoded as key-value pairs, where keys and values are URL-encoded, and each pair is separated by an ampersand (
&).If a form contains two fields,
usernameandpassword, the encoded data might look like:username=johndoe&password=secret123 -
multipart/form-data: This encoding type is used when a form includes file uploads. In this format, each form field is sent as a separate part of the request body, allowing for binary data (like files) to be transmitted. Each part has its own set of headers, including
Content-Dispositionto indicate the form field name and the filename, and optionallyContent-Typeto specify the type of the file.--boundary Content-Disposition: form-data; name="username" johndoe --boundary Content-Disposition: form-data; name="file"; filename="photo.jpg" Content-Type: image/jpeg [binary data] --boundary--
Info
In the above example, --boundary is a delimiter that separates the different parts of the form data.
Content-Type¶
When sending a request body, specifying the Content-Type header is essential to indicate the format of the data being
transmitted. This helps the server understand how to interpret the incoming data.
For example:
-
If you're sending JSON data, you should specify
Content-Type: application/jsonin the request header:POST /api/resource HTTP/1.1 Content-Type: application/json { "name": "Alex", "age": 30 } -
If you're submitting form data with file uploads, the
Content-Typeshould bemultipart/form-datawith a boundary that separates the different parts of the form:POST /upload HTTP/1.1 Content-Type: multipart/form-data; boundary=boundary --boundary Content-Disposition: form-data; name="username" johndoe --boundary Content-Disposition: form-data; name="file"; filename="photo.jpg" Content-Type: image/jpeg [binary data] --boundary-- -
For simple form submissions (without file uploads), the
Content-Typewould typically beapplication/x-www-form-urlencoded:POST /submit HTTP/1.1 Content-Type: application/x-www-form-urlencoded username=johndoe&password=secret
By specifying the correct Content-Type, you ensure that the server can correctly process and interpret the request
body.
Making HTTP Requests in Python¶
The requests module is a popular library in Python that simplifies making HTTP requests. To get started, you first
need to install the module if you haven’t already. You can do this using pip:
pip install requests
Once you have the requests module installed, you can start making various types of HTTP requests, such as GET, POST, PUT, DELETE, and more. For example, to perform a simple GET request, you can use the following code snippet:
import requests
response = requests.get('https://api.example.com/data')
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f'Error: {response.status_code}')
In this example, the get function sends a GET request to the specified URL. The response from the server is stored in the response variable. You can check the response status code to determine whether the request was successful (HTTP status code 200 indicates success). If the request was successful, you can retrieve the JSON data from the response using the json() method.
For making POST requests, the syntax is similar. You can send data to the server as follows:
data = {'key': 'value'}
response = requests.post('https://api.example.com/data', json=data)
This sends a POST request to the specified URL with the provided data formatted as JSON. You can similarly use the put, delete and another methods for updating or deleting resources.
Types of Request Parameters¶
When making HTTP requests, various parameters can be passed to customize the request and convey additional information to the server. These parameters typically fall into several categories: query parameters, body parameters, path parameters, headers, and cookies. Understanding each type helps ensure that your requests are structured correctly for effective communication with APIs.
Query Parameters¶
Query parameters are appended to the URL of an HTTP request and are used to send additional information to the server.
They typically appear after a question mark (?) in the URL and are separated by ampersands (&).
Query parameters are commonly used for filtering, sorting, or paginating data.
Example
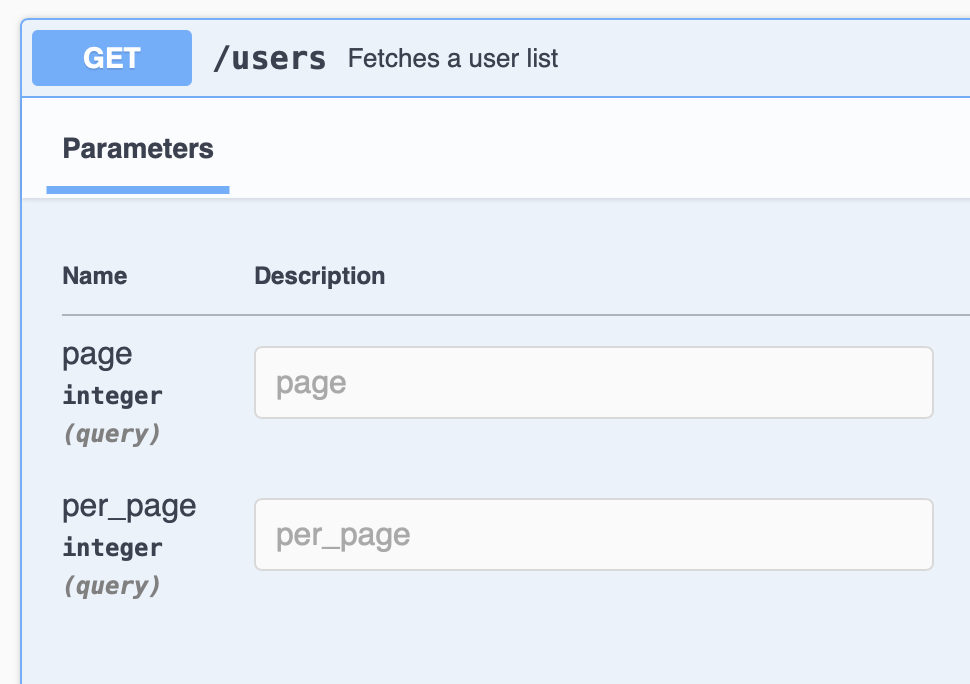
URL with query parameters might look like this:
https://api.example.com/users?page=2&per_page=5
In Python's requests module, you can pass query parameters as a dictionary using the params argument:
import requests
params = {'page': 2, 'per_page': 5}
response = requests.get('https://api.example.com/users', params=params)
Body Parameters¶
Body parameters are used to send data to the server as part of the request body, particularly in POST, PATCH and PUT requests. This data can be sent in various media types, such as JSON, form data, or XML. Body parameters are not visible in the URL and are used for operations that create or update resources.
In Python, for form data or non-JSON data, like XML, you can use the data argument:
import requests
form_data = {'key': 'value', 'another_key': 'another_value'}
response = requests.post('https://api.example.com/data', data=form_data)
For files, you can use the files argument
import requests
files = {'file': open('mynotes.txt')}
response = requests.post('https://api.example.com/data', files=files)
Example
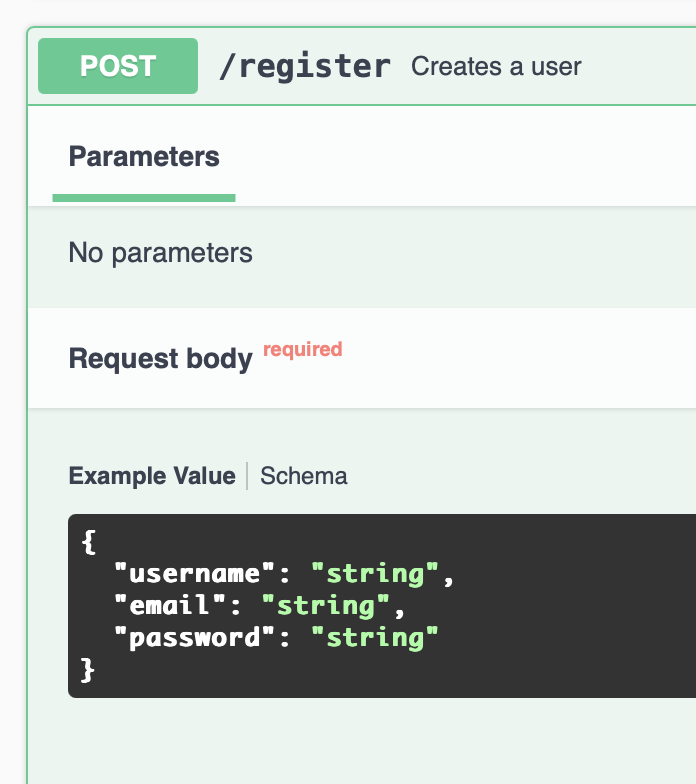
When sending JSON data, you can use the json argument in requests:
import requests
data = {'username': 'bob2003', 'password': 'secret_password', 'email': '[email protected]'}
response = requests.post('https://api.example.com/register', json=data)
Path Parameters¶
Path parameters are used to specify specific resources within the URL. They are part of the URL path and are typically
enclosed in curly braces {} in the API definition. This is related to placeholders. Placeholder is a temporary symbol
used to represent a value that will be provided or substituted later.
Example
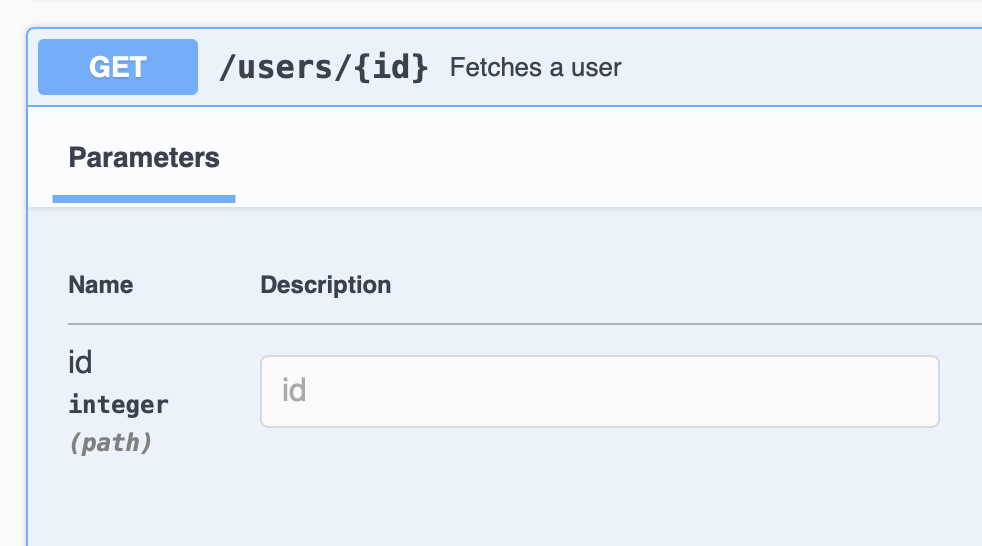
For example, {id} is path parameter (placeholder). In the following URL, 123 is a path parameter
representing a specific user ID:
https://api.example.com/users/123
In requests, you can format the URL string to include path parameters:
import requests
user_id = 123
response = requests.get(f'https://api.example.com/users/{user_id}')
Headers¶
Headers are key-value pairs sent along with the request that provide additional context or metadata about the request. Headers can include information such as content type, authorization tokens, user agents, and more. They are essential for ensuring the server correctly processes the request.
Example
You can pass headers in requests using the headers argument:
import requests
headers = {'Authorization': 'Bearer YOUR_TOKEN', 'Content-Type': 'application/json'}
response = requests.get('https://api.example.com/data', headers=headers)
Cookies¶
Cookies are small pieces of data stored on the client side and sent along with HTTP requests. They are often used for session management, tracking user preferences, or maintaining state between requests. When the server sets a cookie, it can be sent back with subsequent requests to maintain the session or other data.
Example
In requests, you can manage cookies by passing them in the cookies argument:
import requests
cookies = {'session_id': 'your_session_id'}
response = requests.get('https://api.example.com/data', cookies=cookies)
Introducing httpx¶
While the requests library is a popular choice for making HTTP requests in Python, httpx offers several enhancements and modern features that can improve your API interaction experience. Here’s a closer look at httpx, its similarities with requests, the concept of the client, client parameters, and the importance of closing the client.
httpx is a powerful HTTP client for Python that is designed to be an improvement over requests. It not only maintains the simplicity and ease of use found in requests, but it also introduces additional features, including support for asynchronous requests, which allows for non-blocking network calls.
To install httpx, you can use pip:
pip install httpx
Similarities to requests¶
One of the most appealing aspects of httpx is its API design, which closely resembles that of requests. This means that if you're already familiar with requests, transitioning to httpx will feel natural. Both libraries provide similar methods for making GET, POST, PUT, DELETE requests, and so on.
Here are examples of GET and POST requests in both libraries:
Using requests:
import requests
response = requests.get('https://api.example.com/data')
data = response.json()
Using httpx:
import httpx
response = httpx.get('https://api.example.com/data')
data = response.json()
As you can see, the syntax and structure of making requests are almost identical.
Understanding the Client¶
The client in httpx is an essential component that manages connection settings and facilitates making multiple
requests.
You can create a client instance using httpx.Client() for synchronous requests or httpx.AsyncClient() for
asynchronous requests.
Making requests with Client is the same as before
import httpx
client = httpx.Client()
response = client.get('https://api.example.com/data')
if response.status_code == 200:
data = response.json()
print(data)
client.close()
Using a client provides several benefits:
- Connection Pooling: Reuses existing connections for multiple requests to the same host, reducing latency and improving performance.
- Configuration Management: Allows you to define common settings like headers, timeouts, and base URLs in one place, making your code cleaner and more maintainable.
When creating an httpx.Client, you can customize it with several parameters:
-
base_url: A base URL that serves as a prefix for all requests made using the client. This simplifies the construction of endpoints.client = httpx.Client(base_url='https://api.example.com') -
timeout: Defines how long the client should wait for the response before timing out. You can set both connect and read timeouts.timeout = httpx.Timeout(connect=5.0, read=10.0) client = httpx.Client(timeout=timeout) -
headers: Sets default headers for all requests made with the client, which is useful for managing authorization tokens or content types.headers = {'Authorization': 'Bearer YOUR_TOKEN'} client = httpx.Client(headers=headers) -
cookies: Allows you to manage cookies that should be sent with requests, maintaining session state or user preferences.cookies = {'session_id': 'your_session_id'} client = httpx.Client(cookies=cookies)
Warning
Closing the httpx.Client is crucial for proper resource management. When you create a client instance, it opens a connection pool to the specified server(s). If you don't close the client after use, it can lead to several issues:
- Resource Leakage: Open connections may linger indefinitely, consuming system resources and leading to potential memory exhaustion or application slowdowns.
- Graceful Shutdown: Closing the client ensures that any pending requests complete correctly and that resources associated with the client are released.
To ensure the client is closed properly, you can use it within a with statement, which automatically closes the client
when the block is exited:
with httpx.Client() as client:
response = client.get('https://api.example.com/data')
if response.status_code == 200:
data = response.json()
print(data)
Conclusion¶
httpx provides a robust and modern alternative to the requests library, with enhancements such as asynchronous
support and improved client management.
Its API design makes it easy for existing requests users to adopt,
while features like connection pooling and configurable client parameters enhance performance and maintainability.
Closing the client properly ensures efficient use of resources,
making httpx a compelling choice for handling HTTP requests in Python applications.